Se você não é nerd, não tem tempo, não tem coração e não tem curiosidade, recomendo que ignore todo o texto e leia somente o item 3.
Por causa da forma como os álbuns de fotos do UOL são feitas, copiar suas fotos é uma tarefa difícil para a maioria dos usuários. Não acho que a UOL faça assim de propósito, mas por uma questão de usabilidade mesmo: há dois botões enormes em cima das fotos para você avançar para a próxima foto ou voltar para a anterior, e é por causa deles que você não consegue ver o “Copiar endereço da imagem” quando clica com a tecla direita na área da imagem (porque você não está realmente clicando na imagem, mas num botão transparente).
No entanto, há várias formas de copiar fotos dos álbuns da UOL. Neste post apresento algumas. Para testar, você pode tentar aplicar essas ideias neste álbum.
0. Soluções toscas
Como eu disse no início, os webmasters do UOL aparentemente não fazem os álbuns se comportarem assim de propósito, mas por causa de botões gigantes. A maneira mais fácil de copiar uma foto de um álbum do UOL é clicar bem na coluna exatamente no meio dela, evitando as duas setas. Você pode passar o mouse devagar pelo meio da foto até que o seu cursor deixe de ser uma mãozinha e seja uma seta. Pra saber se você deve ir pra esquerda ou pra direita é só ir na direção da seta que você não está vendo.
Outra solução também tosca é simplesmente tirar um screenshot da tela em que você está (apertar a tecla PrintScreen na maioria dos computadores deve funcionar) e recortar a imagem. Eu imagino que essa seja a solução mais usada, mas pessoalmente acho ela terrível.
Não pare de ler! Prometo que as próximas soluções vão ser mais legais.
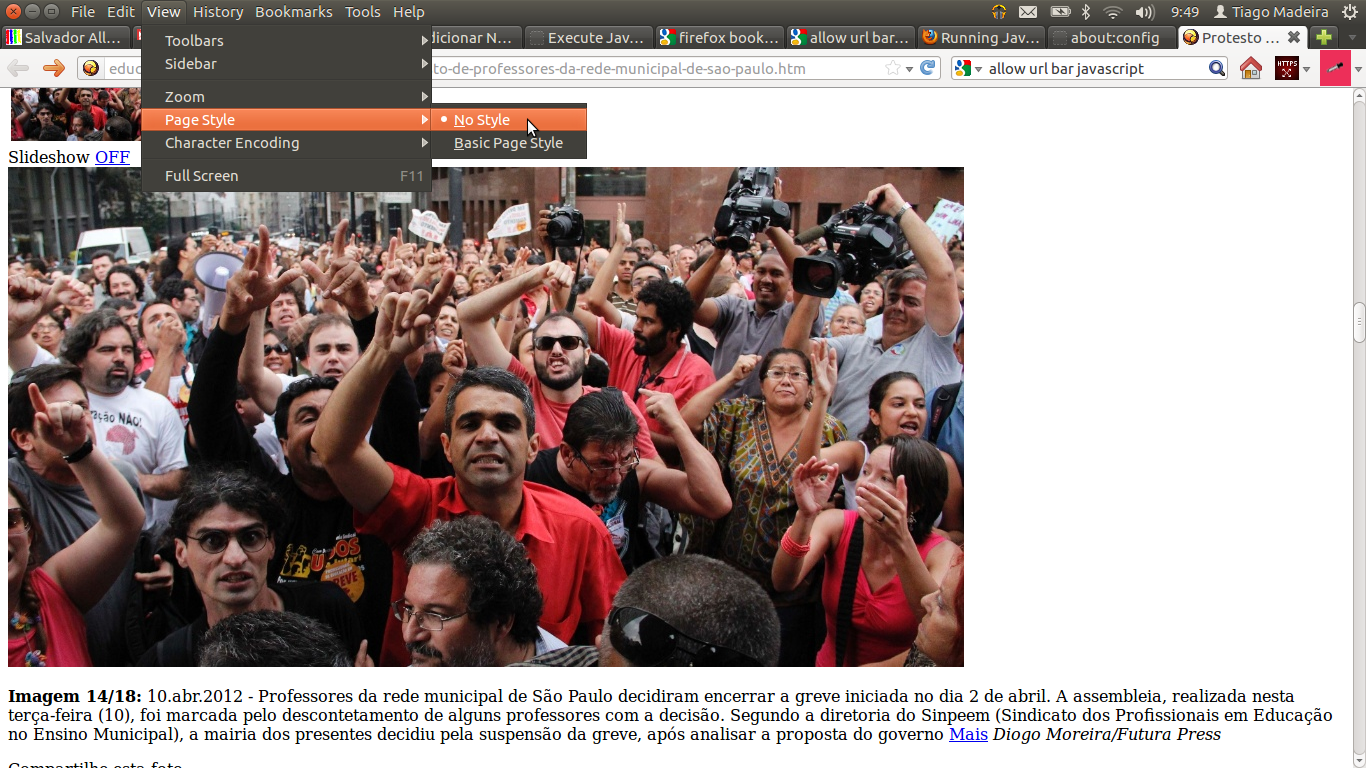
1. Somente para o Firefox: desativar estilos
Desativar o CSS da página é uma forma fácil de acabar com todo seu leiaute e dessa forma copiar a imagem sem se preocupar com perfumarias. Você provavelmente pode fazer isso em qualquer navegador usando plugins (e nos navegadores que não suportam CSS é até mais fácil: você nem precisa fazer nada!) e no Firefox em particular há um botão no menu (Exibir » Estilos » Sem estilos).
2. JavaScript na barra de endereço
Em geral, você pode escrever um script na barra de endereço para executá-lo na página em que você está. Há um tempo atrás todos os navegadores aceitavam isso, mas aparentemente muitos têm desativado esse recurso por questões de segurança, inclusive o Firefox. De qualquer maneira, se seu navegador suportar, você pode simplesmente digitar:
javascript: document.getElementById(
"setaEsq"
).style.width = document.getElementById("setaDir").style.width = "50px";
void 0;na barra de endereço quando estiver na página do álbum do qual quer baixar fotos.
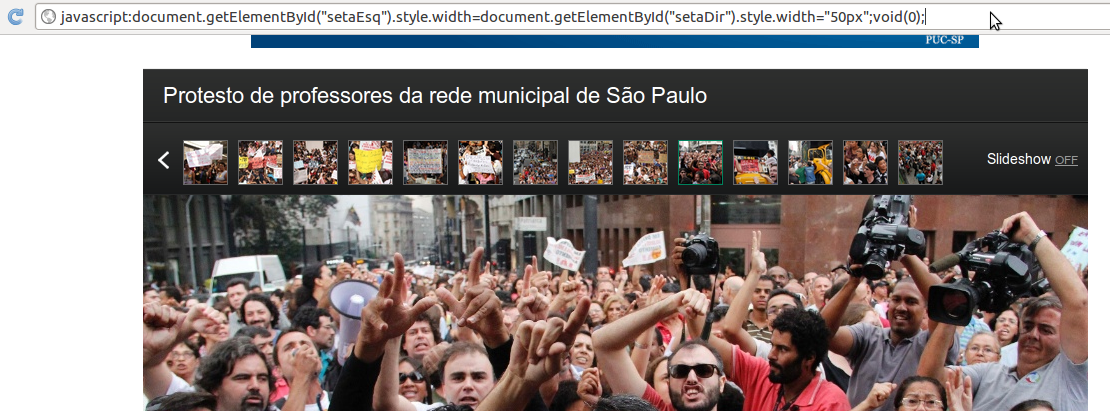
Isso vai reduzir o tamanho dos botões, fazendo com que a área clicável seja bem maior.
Exercício para quem souber ou quiser aprender JavaScript: Escreva um script que abra a foto numa nova aba em vez de simplesmente deixá-la clicável. Transforme-o num bookmarlet (veja o próximo item).
3. Bookmarlet
A solução anterior nos incentiva a criar um botão que execute esse script para não termos que decorá-lo nem copiá-lo sempre. Eis aqui esse botão para você: Aumentar área clicável das fotos dos álbuns da UOL. Clique com a tecla direita nesse link e adicione-o aos seus favoritos. Quando você estiver num álbum, clique nesse favorito e a imagem vai se tornar magicamente clicável :)
4. Firefox e GreaseMonkey
Se você usa Firefox e tem instalada a extensão GreaseMonkey, instale o seguinte user script (que executa o mesmo código que colei no item 2) e sempre que você abrir um álbum as fotos serão clicáveis: Download do userscript
// ==UserScript==
// @name Copiador de fotos UOL
// @description Torna mais fácil copiar fotos de álbuns da UOL
// @author Tiago Madeira <contato@tiagomadeira.com>
// @include http*://*.uol.com.br/album/*
// @version 0.9
// ==/UserScript==
(function () {
window.onload = function () {
document.getElementById("setaEsq").style.width = "50px";
document.getElementById("setaDir").style.width = "50px";
};
})();Mas estou lendo este post em 2020 e o UOL mudou! Ou eu quero baixar fotos do site X, não do UOL!
A solução 1 (desativar estilos) funciona em 99% dos casos. Não quer ver sites sem estilo? Continue lendo.
5. Se você não quiser utilizá-la e se você estiver usando Firefox, pode clicar no ícone ao lado do endereço do site na barra de endereço e aí no botão “Mais informações”. Isso vai abrir uma tela com uma seção “Mídia” onde é possível ver e salvar imagens, ícones e vídeos que seu navegador baixou para mostrar a página. Esse método funciona também para copiar vídeos HTML5, inclusive do YouTube:
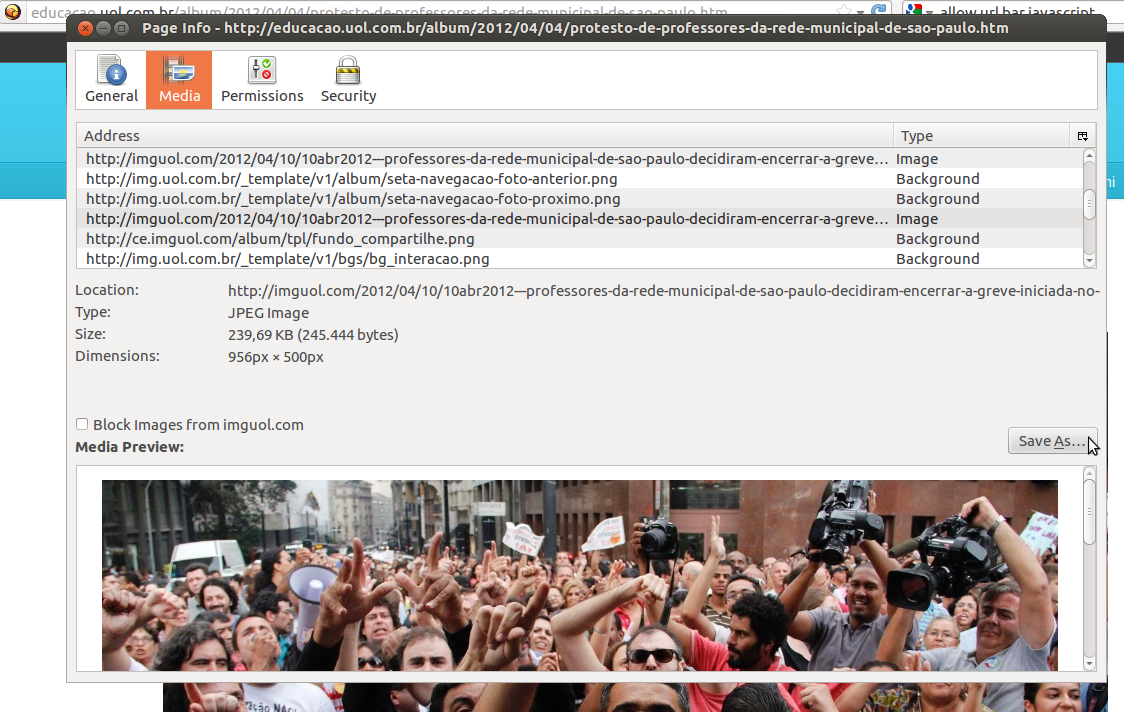
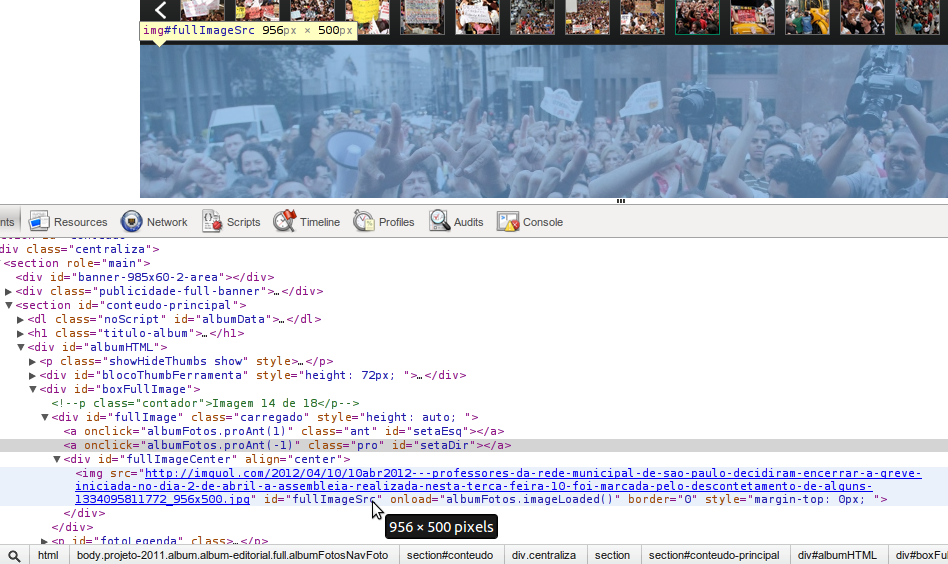
6. Se você não quiser procurar uma imagem no meio de um monte de mídias, a última versão do seu navegador deve ter um botão “Inspecionar elemento” no menu de contexto sempre que você clica com a tecla direita em qualquer lugar da página. Usando essa ferramenta é possível ver o código HTML do que você está vendo (ela é diferente e melhor do que simplesmente ver o código-fonte da página porque usando a inspeção de elementos você vê o código do momento atual, depois dos scripts mudarem as coisas). Se você pedir para inspecionar alguma coisa transparente em cima da imagem, em geral não vai ser difícil achar a própria imagem. Este screenshot é do Chrome:
Há inúmeras soluções mais nerds, mas quis manter a lista com sugestões fáceis e que não precisam de nada além do seu navegador. Alguma outra ideia simples, criativa e divertida? Blogue por aí ou me conte pra eu aumentar a lista!