Alguns sites começaram a abusar de um recurso super interessante do JavaScript para acabar com uma das características mais importantes da Internet: a capacidade de copiar/colar.
O tratamento dos clipboard events (oncut, oncopy e onpaste) deveria servir para permitir que os programadores façam coisas legais quando você copia/cola um texto (por exemplo, um processador de textos online pode inserir/remover formatação), mas tenho visto cada vez mais ele ser usado para adicionar uma mensagem de copyright no final de um texto copiado, impedir usuários leigos de copiarem textos na web e evitar que se cole coisas que você copiou em formulários.
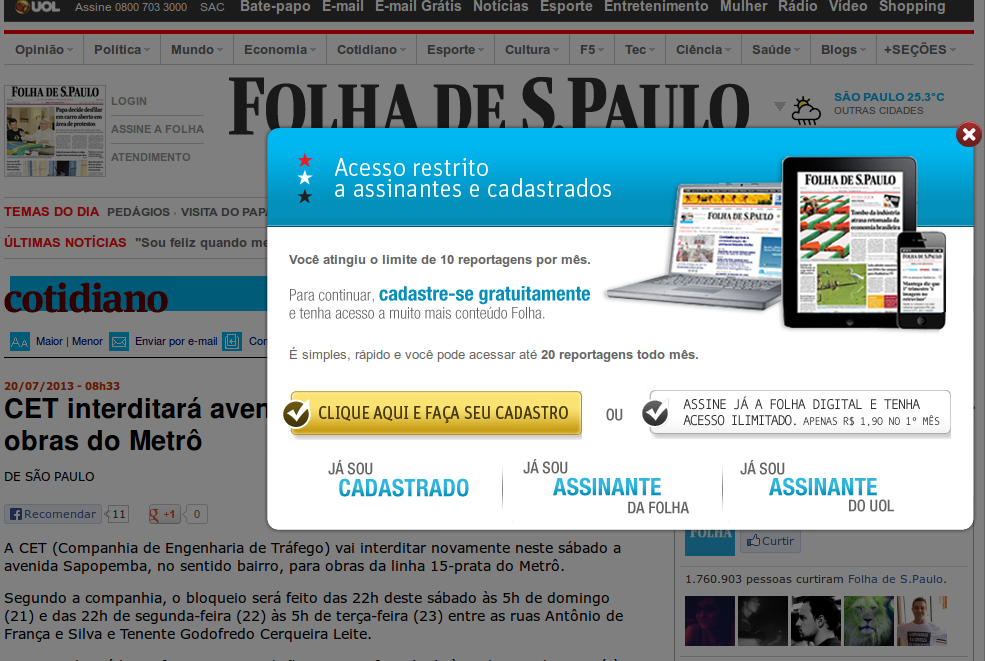
O que mais me incomoda (e que me levou a escrever esta postagem) é que, hoje, quem copia um trecho de uma reportagem da Folha (para guardar, compartilhar numa rede social ou o que quer que seja) acaba colando:
Para compartilhar esse conteúdo, por favor utilize o link http://www1.folha.uol.com.br/fsp/bla-bla-bla ou as ferramentas oferecidas na página. Textos, fotos, artes e vídeos da Folha estão protegidos pela legislação brasileira sobre direito autoral. Não reproduza o conteúdo do jornal em qualquer meio de comunicação, eletrônico ou impresso, sem autorização da Folhapress (pesquisa@folhapress.com.br). As regras têm como objetivo proteger o investimento que a Folha faz na qualidade de seu jornalismo. Se precisa copiar trecho de texto da Folha para uso privado, por favor logue-se como assinante ou cadastrado.
Não é incrível (e sintomático) que o grupo que gerencia o portal mais importante da Internet no Brasil (UOL) tenha uma concepção tão atrasada da rede? Ok, não dá nem pra dizer que isso nos surpreende depois da censura da Falha e do paywall.
Sem mais delongas: isso merece ser hackeado. Neste post, proponho algumas soluções simples para você poder voltar a copiar e colar no seu navegador como sempre fez. Minha preferida, como sempre, é a última.
Solução trivial para quem usa Linux
Antes de sugerir soluções de verdade, convém observar que quem usa Linux (X11) pode copiar selecionando um texto (sem apertar Ctrl+C ou qualquer outra combinação esdrúxula de teclas) e colar apertando o botão do meio do mouse. Quando se copia/cola dessa forma, o navegador não emite os temidos eventos oncopy/onpaste (ou seja, tudo funciona normalmente).
Rodolfo Mohr também observou que você pode copiar um texto selecionando-o, clicando com a tecla direita na seleção e em “Pesquisar no Google”. Uma aba vai abrir com a pesquisa no Google e você pode copiar o texto lá. É um hack válido, embora incômodo.
Somente Firefox: usando about:config
Se você usa Firefox, pode desabilitar os clipboard events digitando, na barra de endereços, em about:config. Talvez ele diga que é perigoso e peça para você clicar num botão dizendo que sabe o que está fazendo. Pode confiar. Em seguida, procure a chave dom.event.clipboardevents.enabled e clique duas vezes nela para mudar seu valor para false. Reiniciando o navegador, o recurso copiar/colar estará funcionando normalmente (ou talvez nem precise reiniciá-lo).
Extensões (para Firefox, Chrome e Opera)
Não tem o que explicar. Simplesmente clique no nome do seu navegador e instale: Firefox, Chrome, Opera.
Editado em 01/04/2014, 22:30: A extensão que eu havia colocado para Chrome só desabilita o tratamento de eventos onpaste em formulários. Se você conhecer alguma extensão similar a do Firefox ou a do Opera, me avise pelos comentários.
Desabilitando sob demanda via JavaScript
É muito importante ter em mente que aplicações web como processadores de texto podem usar os eventos oncut/oncopy/onpaste para coisas úteis. Por isso, é desejável desabilitar esses eventos somente em sites específicos.
Não encontrei nenhuma extensão que faça isso, mas um código simples em JavaScript para recuperar o comportamento padrão dos eventos em um determinado site (testei no Firefox e no Chrome) é:
all = document.querySelectorAll("*");
fn = function (e) {
e.stopPropagation();
return true;
};
for (var i = 0; i < all.length; i++) {
all[i].oncut = fn;
all[i].oncopy = fn;
all[i].onpaste = fn;
}Se digitarmos isso no console (Shift+Ctrl+J), as funções copiar/colar devem voltar a funcionar.
Userscript
A solução anterior nos permite criar um userscript para desabilitar o tratamento dos eventos apenas no site da Folha:
// ==UserScript==
// @name Permite copiar textos da Folha
// @include http://*.folha.uol.com.br/*
// ==/UserScript==
window.onload = function () {
all = document.querySelectorAll("*");
fn = function (e) {
e.stopPropagation();
return true;
};
for (var i = 0; i < all.length; i++) {
all[i].oncut = fn;
all[i].oncopy = fn;
all[i].onpaste = fn;
}
};Portanto, se você quiser copiar do site da Folha sem preocupações (e sem desabilitar os eventos em outros sites), pode instalar as extensões GreaseMonkey (Firefox) ou TamperMonkey (Chrome), e então esse userscript clicando neste link: falha.user.js.
Bookmarlet
Acho o método acima (do userscript) o melhor para copiar da Folha. No entanto, é conveniente ter um método mais genérico. Por isso, criei um bookmarklet, isso é, um pequeno script que podemos executar clicando num botão na barra de favoritos (neste caso, para restaurar o comportamento padrão das funções copiar/colar).
Aqui está ele: Restaurar copiar/colar
Para instalar, arraste esse link para sua barra de favoritos. Para usar, clique sempre que precisar copiar um texto e então copie normalmente.
Viva a Internet!